What You're Buying When You Buy an AI Product

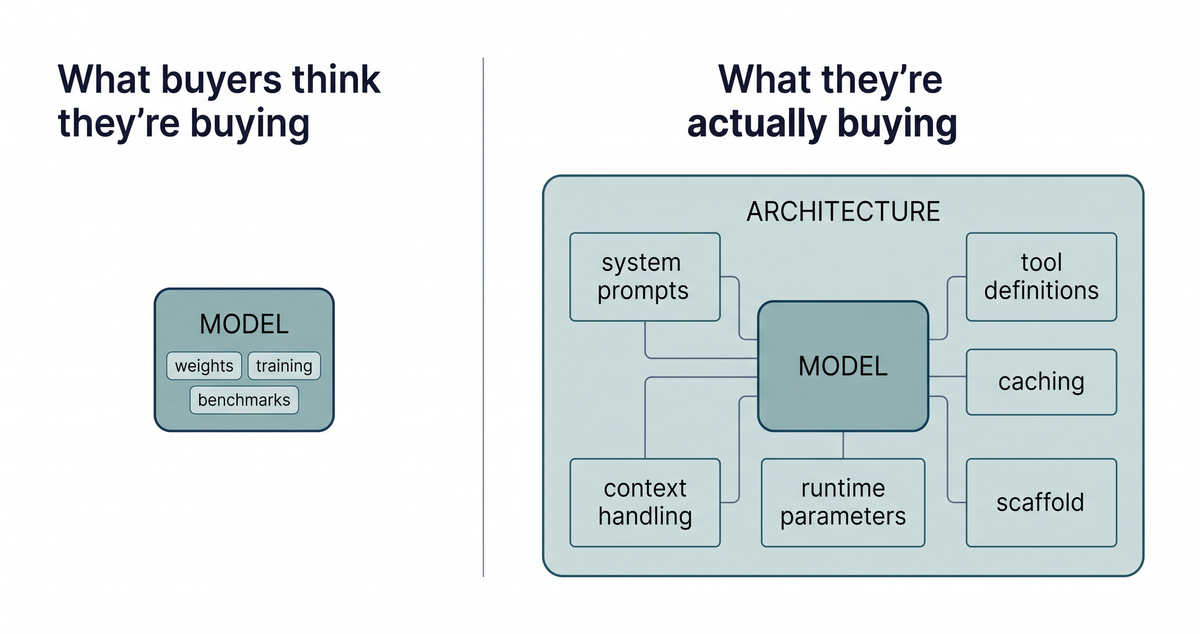
Our position for months has been that the harness around a model, its scaffold, prompts, and configuration, does more work than its weights on whether the product holds up in production. The AI market is still mispricing this. Procurement and investment decisions anchor on model capability: benchmarks, parameter counts, training scale. These matter. They are not the whole story. The architecture around the model, how it manages context, picks tools, retains memory across a session, behaves when something unfamiliar arrives, often carries more weight on outcomes. Capability is where the market spends. Architecture is where the value actually lives.
That gap got measured in public on April 23, when Anthropic published a postmortem on roughly seven weeks of quality degradation in Claude Code, the Claude Agent SDK, and Claude Cowork.
The two surfaces
An AI product has two commercial surfaces, and they behave nothing alike.
Capability moves with training. The work is slow and expensive: billions of dollars and months to produce a new set of model weights. It is also visible, which is what investors fund and boards ask about.
Architecture moves cheap and fast. Most of it is invisible. Changes happen at the prompt, scaffold, and configuration layer: system prompts and tool definitions, caching and context-handling rules, runtime parameters like reasoning effort. A hundred words of well-aimed instruction can change system behavior more than a vendor swap. So can a single toggled parameter. Every AI product has this layer. If you buy a packaged product, the vendor builds it and you inherit its quality. If you build on a raw API, your engineering team builds it and you inherit theirs. Either way, someone owns it. Most organizations have not noticed they own it.
What April 23 proved
Anthropic traced the degradation to three changes. None were retraining runs. All three were small reversions at the configuration and prompt layer.
A March 4 default-effort reduction, shipped deliberately to cut latency, that turned out to degrade reasoning more than expected. Three weeks later, a caching optimization went out with a bug that silently cleared Claude's prior thinking every turn after a session went idle, producing the forgetfulness users reported. The third change, an April 16 system prompt addition meant to reduce verbosity, dropped intelligence by about three percent on broader evaluations the team ran only after the fact.
The first one is the interesting one. Not a bug. Just a considered product tradeoff that looked right at the time, reversed weeks later when users told the team it wasn't. Accidents and tradeoffs both land at the same layer.
The cache bug made it past automated tests, multiple human and automated code reviews, end-to-end tests, and continuous internal staff usage. Two unrelated internal experiments happened to mask it from the engineers most likely to catch it. Even Anthropic, which has spent more time on context engineering than most labs, couldn't tell its own product was degrading.
When Anthropic finally back-tested its Code Review tool against the offending pull requests, Opus 4.7 caught the bug. Opus 4.6, the model running in production when the change shipped, did not. Newer architecture, given full repository context, found what the older architecture missed.
In a study we ran the same week, a frontier model read nine debugging traces (three from itself, six from peer models) and articulated in 101 words the exploration pattern that distinguished the passing runs from the failing ones. Pasted into its own system prompt, those 101 words cut its tool-call rounds on the same task by 40.5 percent. Capability untouched. Architecture rewritten by paragraph.
Why "we use it ourselves" stops working
Dogfooding has been an industry shorthand for trust since the 1990s. It was a strong signal for traditional software, where regressions were usually visible: a button broke, a page failed to load, a calculation returned the wrong number. AI products fail differently. The model still answers. Tools still execute. The session completes; the output is just quietly worse, and it surfaces months later as churn that no one quite traces back.
Anthropic dogfooded Claude Code continuously through the degradation and didn't detect it. If that's the standard of evidence available from the highest-resourced AI lab in the world, "our engineers use it daily" has stopped doing the work it used to do.
The buyer-side discipline
The real differentiation in the AI market is not between frontier labs. On a five-skill agentic-coding benchmark we ran in April, three frontier models, Opus 4.7, GPT-5.4, and Gemini 3.1 Pro, passed every skill at 100 percent. What separated them was cost and tool-round efficiency: how many turns each model needed to reach the same correct outcome, which is a function of scaffold and prompt configuration, not model weights. Across most workloads, frontier capability is closer than aggregate leaderboards suggest. The variance that matters lives in the layer around the model.
What is not converging is whether your organization can detect when the AI it already runs has quietly stopped working. The buyers who get this right tend to do two things. They measure their AI deployments against their own workflow baselines, weekly, because no vendor can tell them whether the product is working for their specific use case. And they treat system prompts, tool definitions, and context-handling rules as first-class production infrastructure: version-locked and fingerprinted, with alerts on drift.
A procurement implication follows from the postmortem itself. Anthropic's disclosure is a trust deposit, and it sets a comparator. Some buyers are already demanding equivalent transparency from their other AI vendors and switching when they don't get it. They're evaluating on a different axis than buyers still comparing price per million tokens.
Roughly seven weeks of silent degradation at the best-instrumented AI lab in the world is not an accident. It is what this market shape produces. The funding still goes to capability; the outcomes increasingly come from the layer most buyers haven't noticed they own. Buyers who measure that layer catch regressions in days. For everyone else, the cost surfaces two or three quarters later, and never as a single signal. Customer acquisition drifts. Churn cohorts underperform and nobody can quite say why; support volume creeps up alongside. Leadership blames the model or the vendor. The configuration change three quarters back is rarely on the suspect list.