What We Learned by Watching One Model Watch Another

A frontier AI model read nine labeled debugging traces — three from itself, three from each of two peer models, all on the same bug. In a single API call it wrote 101 words describing what the peers did that it didn't. Those 101 words, pasted verbatim into its own system prompt, cut its tool-call rounds on the same bug by 40.5% on the next 10 runs. Test correctness was identical. Judge scores were identical. No fine-tuning, no new model, no new training data.
Inside the paragraph it also named one specific anti-pattern that only appeared in its own failing traces. We never asked it to identify which runs were its.
What follows is a short case study of what the experiment measured, and what the finding does and does not support.
1. A strange gap
Three frontier AI models faced the same bug: a race condition in a Python producer-consumer queue. Same tests, same tools, same budget of 15 tool-calling rounds. Two of them solved it. One ran out of budget and failed, twice out of three tries.
The losing model is not the weak one. On a different skill in the same benchmark, fixing a broken build, it was the fastest of the three. It is the slowest on this one, and a fact-check against every skill in the run shows the gap is skill-specific, not model-general.
| Model (April 2026) | Concurrency runs | Pass rate | Mean rounds |
|---|---|---|---|
| Claude Opus 4.7 | 10, 9, 13 | 3/3 | 10.7 |
| Gemini 3.1 Pro | 10, 10, 11 | 3/3 | 10.3 |
| GPT-5.4 | 15, 10, 15 | 1/3 | 13.3 |
A "round" here is one back-and-forth between the model and its tools: the model asks to read a file or run a command, the tool responds, the model decides what to do next. Two of these models converge in 10 rounds on this bug. One does not finish in 15.
What we wanted to know was whether reading every tool call of every run, side by side, would show us what the gap actually was, and whether the gap could be closed by words alone. Specifically: could the underperforming model, given a carefully labeled view of its peers' behavior, write the instruction that fixed itself?
2. The gap is one skill, not the model
Before guessing that one model is behind the others, the same benchmark on four other bug-fix skills tells a different story. Mean rounds used, same three models, same conditions:
| Skill | Opus | Gemini | GPT-5.4 |
|---|---|---|---|
| Fix a broken build | 7.7 | 11.0 | 7.0 — fastest |
| Multi-step data migration | 9.0 | 10.0 | 10.3 |
| Security review & fix | 8.7 | 8.0 | 10.3 |
| Fix a cross-file bug | 7.0 | 10.7 | 11.0 |
| Fix a concurrency bug | 10.7 | 10.3 | 13.3 — slowest |
GPT-5.4 is the most efficient model on broken-build, mid-pack on migration and security, and distinctly slowest on concurrency (and somewhat on cross-file debugging). There's no "one model is worse" story in the data. There is a "concurrency trips up this specific model" story.
3. How we read the traces
Each of the 9 concurrency runs produced a full record: every file the model read, every command it ran, in order. We categorized each tool call by purpose, using four labels fixed in advance:
- Information-gathering — reading or searching a new source
- Hypothesis-verification — running a test, or checking a specific claim
- Edit-commit — actually writing a fix
- Re-verification — reading or running something already seen, with no state change in between
The categorization rules were committed to our pre-registered research plan before we looked at any of the traces, so we couldn't re-slice the categories to flatter our hypothesis.
Two concrete findings emerged from the coding pass:
- GPT-5.4's redundancy rate: 1.89%. Out of 53 tool calls across its three runs, exactly one was a pure re-read of something already seen. Our pre-registered threshold for "the model is stuck in a loop" was 15%, so the obvious hypothesis, that GPT-5.4 burns rounds on paranoid re-verification, is false.
- Sequence similarity. We computed a call-sequence-distance between every pair of runs (a standard edit-distance metric on the categorized sequences). Opus and Gemini's runs land at 0.245 apart on average; one Opus run and one Gemini run produce identical sequences. GPT-5.4's runs sit 0.42–0.45 from either reference model. Two models are following the same shape; one is following a different shape.
GPT-5.4 isn't looping. Something about its exploration is structurally different.
4. What the traces actually show
Three traces, side by side. All three models, same bug.
Claude Opus 4.7, run 1 (9 rounds, passed, quality 0.967):
1. read_multiple_files queue.py, crawler.py, test_crawler.py, test_legacy.py
2. list_allowed_directories
3. directory_tree (the workspace)
4. read_multiple_files (same files, via absolute paths)
5. run_command bash run_tests.sh ← reproduces failure
6. run_command which python3 && ... ← one interpreter check
7. write_file queue.py (the fix)
8. run_command pytest tests/ -x -v ← verify
9. run_command for i in seq 1 20; do pytest ← stress loop
One batch read of the implicated code. One test run that reproduces the failure. One edit. A quick verify plus a stress loop. Nine rounds, done.
Gemini 3.1 Pro, run 0 (10 rounds, passed, quality 0.927):
1. run_command bash run_tests.sh ← reproduces failure FIRST
2. read_text_file run_tests.sh
3. list_allowed_directories
4. list_directory (workspace)
5. read_text_file run_tests.sh (absolute path)
6. run_command pytest tests/ -x -v
7. read_multiple_files src/scraper/*
8. edit_file queue.py (the fix)
9. run_command pytest tests/ -x -v ← verify
10. run_command cat tests/test_crawler.py
A different order, but the same shape: reproduce the failure first, read a narrow set of implicated files, one edit, verify. Ten rounds, done.
GPT-5.4, run 0 (15 rounds, FAILED, ran out of budget, quality 0.0):
1. list_allowed_directories
2. list_directory_with_sizes
3. directory_tree ← three ways of listing
4. run_command find src tests -maxdepth 3
5. read_text_file AGENTS.md (2000-char chunks)
6. read_text_file queue.py (400-char chunks) ← chunked
7. read_text_file crawler.py (400-char chunks)
8. read_text_file test_crawler.py (400-char chunks)
9. read_text_file test_legacy.py
10. read_text_file run_tests.sh
11. read_multiple_files (re-batches everything)
12. read_multiple_files (same files, absolute paths) ← re-read after path shift
13. run_command bash run_tests.sh
14. run_command python3 -m pytest
15. read_text_file src/... (again)
16. read_text_file README.md ← peripheral
17. run_command sed README.md && pyproject.toml ← peripheral
18. run_command git log --oneline && git blame ← peripheral
19. write_file queue.py (the fix — round 18, past ceiling)
20. run_command pytest (never completes)
21. run_command stress test (never completes)
Before writing any fix, the model has listed the workspace three different ways, read the source files in 400-character chunks (instead of in full), re-read the same files a second time after a filesystem-root shift, read the project README and configuration, and consulted git history. The first edit does not appear until round 18, three rounds past the ceiling.
Every read brings new information, so the redundancy rate stays near zero. There are simply more sources being consulted. We named this pattern breadth-of-enumeration: reading more things before committing to a fix, rather than re-reading the same things repeatedly.
This is the shape of the gap.
5. Showing the model what we showed ourselves
The obvious next move is to write a one-paragraph instruction, something like "commit on first plausible hypothesis, skip the README and git history, read source files in full," and drop it into GPT-5.4's system prompt. We almost did that.
The more interesting move was to skip the authoring step.
GPT-5.4 has access to the same trace data we do. If the pattern is legible to a human reader from the three sequences above, is it legible to the model? Can the subject write the intervention from the evidence? The honest way to find out is to ask.
5.1 What we handed the model
We built a nine-trace digest from the raw benchmark output, with every run labeled by the model that produced it, every tool call listed in order, plus headline metrics (pass/fail, rounds, quality score). No reasoning text — only the tool-call shape. The digest explicitly tells the model which runs passed and which ran out of budget.
In other words: exactly the kind of table the reader of this article just scrolled through in §4, only with all nine runs instead of three excerpts.
5.2 What we asked
One API call, to GPT-5.4 itself, with the following prompt, frozen in our pre-registration before we fired the call so we couldn't re-tune it to get a better answer:
You are shown 9 debugging traces: 3 runs each from three frontier models (Claude Opus 4.7, Gemini 3.1 Pro, and GPT-5.4) attempting the same single-file concurrency-bug fix. Each trace lists the sequence of tool calls the model issued, in order, along with whether the run passed and its round count.
Read all 9 traces. Describe, in one paragraph, the exploration pattern that distinguishes the two models that reliably passed from the model that sometimes hit the round ceiling without finishing. Your paragraph should be written as an instruction a debugging agent could follow — concrete behaviors, not abstractions. Do not mention specific tool names. Do not reference any model by name in the paragraph. One paragraph, ≤ 150 words.
Fire-once policy. If the model returned noise or platitudes, that was the result — no silent retries with a better prompt.
5.3 What GPT-5.4 wrote
Verbatim, 101 words, $0.05 of API cost, 37 seconds wall time, one round trip:
After locating the workspace, keep your search narrow: inspect the test runner, the failing concurrency test, and the queue/crawler code, reproduce the failure early, make the synchronization fix in the queue module in one focused edit, then immediately rerun the test suite and a repeated stress loop, stopping once it is stable. If the runner has an environment issue, do one quick interpreter/setup check and continue. Avoid spending rounds on repo-wide inventories, rereading the same files through multiple paths, opening README/build/config/docs or version-control history, or patching extra files speculatively; every additional read or edit should be driven by the failing test.
One sentence of what to do. One sentence of an exception for setup problems. One sentence of what to avoid. 101 words.
5.4 Where each instruction comes from
This is the part that took us by surprise. Every clause in the articulation corresponds to an observable pattern, or anti-pattern, in the traces the model read. The mapping works left to right, line by line:
| GPT-5.4's clause | Pattern in the traces |
|---|---|
| "inspect the test runner, the failing concurrency test, and the queue/crawler code" | All six Opus and Gemini runs open with a batch read of exactly this narrow file set. GPT-5.4's failing runs drift into AGENTS.md, READMEs, configuration files. |
| "reproduce the failure early" | Every Gemini run issues bash run_tests.sh as its first tool call — reproducing failure before reading anything. GPT-5.4's failing runs don't reach the test invocation until round 13. |
| "make the synchronization fix in the queue module in one focused edit" | All six Opus and Gemini runs contain exactly one edit, to the queue module. GPT-5.4's failing run 2 has two edits (queue and crawler). |
| "immediately rerun the test suite and a repeated stress loop" | Opus run 0 closes with a 20-iteration stress loop on the concurrency stress test. Four of the six passing runs close with the same shape. |
| "if the runner has an environment issue, do one quick interpreter/setup check" | Opus run 2 resolves a Python-version PATH issue with two calls (which python3 + a binary lookup). GPT-5.4's own passing run does the same. |
| "avoid spending rounds on repo-wide inventories" | GPT-5.4's failing run 0 lists the workspace four different ways in the first four calls. Opus and Gemini list it once or twice. |
| "rereading the same files through multiple paths" | GPT-5.4's failing run 0, calls 11 and 12: the same source files read twice, first with relative paths and then with absolute paths after a filesystem-root shift. |
| "opening README/build/config/docs or version-control history" | GPT-5.4's failing run 0, calls 16–18: README.md, then pyproject.toml, then git log --oneline plus git blame queue.py. None of these appear in any Opus or Gemini trace on this skill. |
| "patching extra files speculatively" | GPT-5.4's failing run 2 issues two edits, to two different files. All passing runs — every single one — fix the bug in one file. |
Every instruction in the paragraph is anchored in a pattern someone could point to in the data. This isn't the model reciting generic debugging advice it learned somewhere. It's the model reporting what it observed.
5.5 The unprompted self-recognition
The prompt asked the model to describe what distinguishes the passing runs from the failing ones. It did not ask the model to identify which runs were its own, or to name its own mistakes.
But the paragraph contains this clause, unprompted: "avoid rereading the same files through multiple paths."
That is the exact behavior visible in GPT-5.4's own failing trace, calls 11 and 12 of run 0: it read the source files with relative paths, then read the same files again with absolute paths after the filesystem-root changed. No peer model does this anywhere in the data. It is a GPT-5.4-specific anti-pattern.
The model observed itself failing, in a digest of nine labeled traces (three of which it produced, two of which failed), and described the specific behavior to avoid, without being asked to identify itself in the data.
That is the moment we wrote this article about.
6. Installing the instruction, and what happened
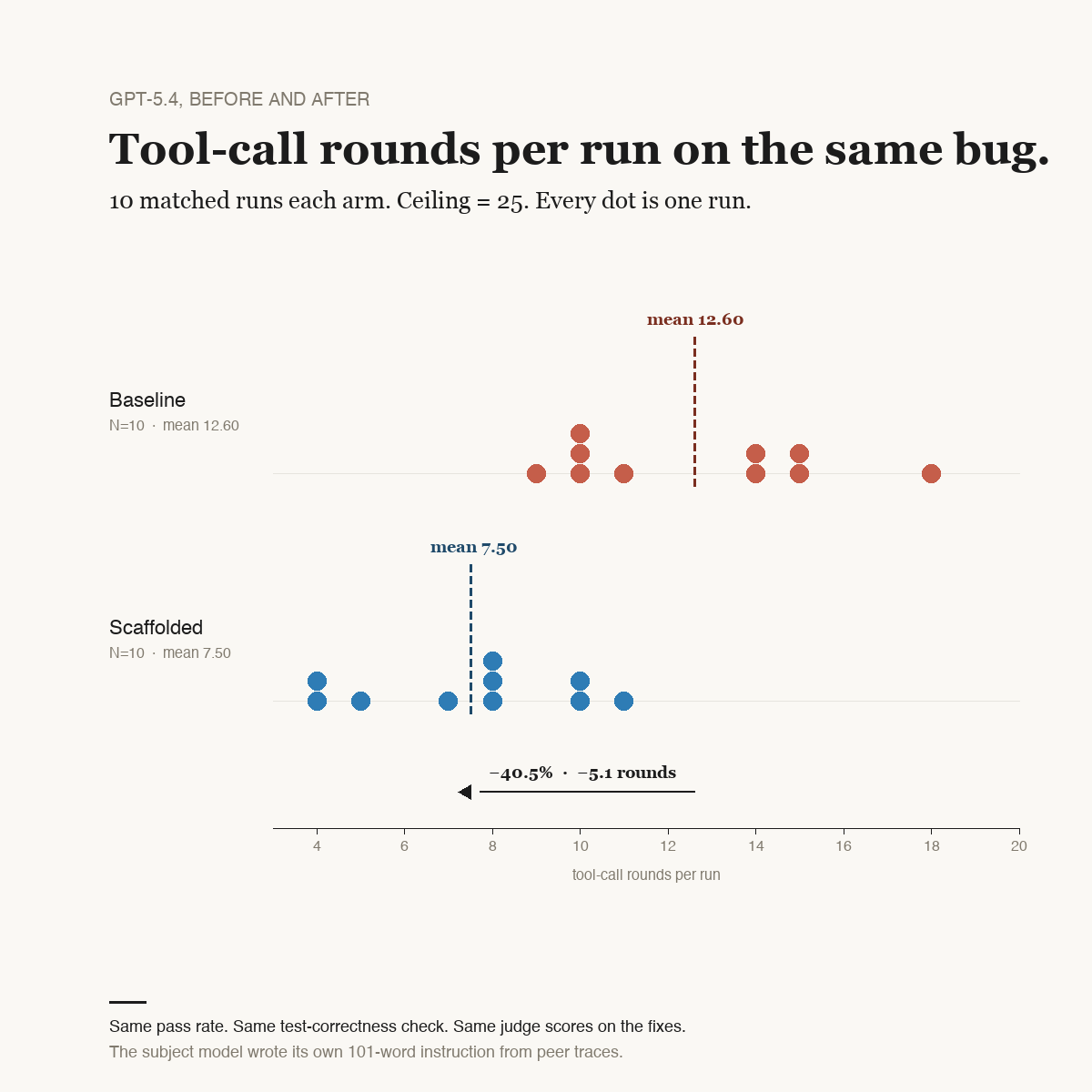
Paste GPT-5.4's 101 words — byte-for-byte, no editing, no polishing — into GPT-5.4's own system prompt. Re-run the same concurrency-bug skill, 10 runs with no scaffold (baseline) and 10 runs with the scaffold prepended, matched conditions, same tests, same ensemble judge:
| Metric | Baseline (N=10) | Scaffolded (N=10) | Delta |
|---|---|---|---|
| Pass rate | 10/10 | 10/10 | 0 |
| Mean rounds used | 12.60 | 7.50 | −40.5% |
| Test-correctness check | 10/10 | 10/10 | 0 |
| Ensemble-judge score | 0.978 | 0.994 | +0.016 |
| Composite quality | 0.814 | 0.941 | +15.6% |
| Cost of the 10-run arm | $6.38 | $2.49 | −61% |
Each dot is one run. The baseline distribution (9–18 rounds) and the scaffolded distribution (4–11 rounds) are nearly separated, with only the three-round band at 10–11 overlapping. The 40.5% mean reduction is not a small shift in a noisy distribution; it is two distinct clusters.
Precise framing matters here. The test-correctness check, which is the actual assertion that says "does this code fix the bug?", passes on every run of both arms. The judge panel scores both arms at near-identical levels (0.978 vs 0.994). The composite quality score rises by 15.6%, but mechanically: the composite weights process efficiency at 20%, and the scaffolded arm uses dramatically fewer calls, so it scores higher on that sub-rule.
The scaffold makes the process leaner. It does not make the fix better than baseline's already-perfect fixes. Both arms produce equivalent fixes, and the scaffolded arm arrives at them in 40.5% fewer rounds at 61% less cost.
A 40.5% round reduction is large enough that our pre-registration flagged anything above 40% as "too-good-to-trust; inspect before publishing." Two checks passed cleanly: no run in either arm hit the tool-round ceiling (top baseline was 18 rounds, top scaffolded was 11, both under the 25 cap), and the judge panel did not silently favor the scaffolded arm (the judge delta of 0.016 is noise).
7. Does the habit transfer?
Every intervention faces the same question: did we just overfit to the one skill we designed it against?
Our pre-registration required us to test this. The scaffold was written from concurrency traces; we applied it, unchanged, to a different skill in the same benchmark (cross-file debugging), also a task where GPT-5.4 struggled in the original run. Same 10+10 matched design:
| Metric | Baseline | Scaffolded | Delta | Pre-reg threshold |
|---|---|---|---|---|
| Pass rate | 10/10 | 10/10 | 0 | no loss — ✓ |
| Mean rounds | 6.60 | 6.40 | −3.0% | ≥15% — ✗ |
| Quality score | 0.978 | 0.992 | +1.4% | no loss — ✓ |
By the letter of our pre-registration, the scaffold fails to transfer: we required ≥15% round reduction on this second skill, and got 3%.
But look at the baseline number. On this skill, GPT-5.4's un-scaffolded runs already average 6.60 rounds. Opus 4.7's best previous run on the same skill, in the same benchmark, averaged 7.0 rounds. GPT-5.4 was already at or below peer-efficient levels at baseline. There was no over-enumeration pattern present; the scaffold's target wasn't there to compress.
The scaffold didn't fail because it didn't transfer. It was inert — it didn't help and didn't hurt, costs are flat, quality is equivalent. The scaffold corrects the over-enumeration pattern on skills that exhibit it, and is a no-op on skills that don't.
For the business reader: the intervention is diagnostic-specific. Apply it where the subject model shows the enumeration pattern at baseline; don't expect it to help where the model is already efficient; don't expect it to hurt either.
8. What this means
Modern AI models have at least two distinct surfaces that producers of AI-powered software care about:
- Capability — what the model can do given unlimited compute and perfect prompting. Reasoning depth, tool proficiency, and breadth of knowledge. Moving capability requires training: billions of dollars, months of work, and new weights.
- Architecture — how the model prefers to navigate under uncertainty. Its default exploration strategy, commitment thresholds, and verification habits. Apparently, editable in-context, sometimes by 101 words.
The mechanism in this case study is not complex:
- The subject model reads a labeled digest of peer traces.
- The subject model articulates the pattern it sees, in one paragraph.
- That paragraph is pasted into the subject model's own system prompt.
- The subject model runs the task under its own instruction.
No fine-tuning, no weight updates, no retrieval-augmented generation, no training-data changes. The articulation cost five cents. The full 10-run scaffolded arm cost $2.49. The loop closes on itself — the model doing the observing is the same model doing the task.
The bounded claim from this study has two conditions. First, the subject model shows a specific per-skill behavioral gap against peer models. Second, the mechanism behind the gap is how the subject commits to hypotheses under uncertainty, rather than whether it can reason its way through the problem at all. Where both hold, asking the subject model to articulate the peer pattern and pasting its answer into its own system prompt can close the gap. On the concurrency skill, it did: 40.5% fewer rounds, equivalent correctness.
The bounded claim does not extend to every skill, every model, or every gap. §7 made that clear. The intervention itself is diagnostic-specific. The methodology — read peer traces, articulate, install, measure — is what travels.
For agentic-system builders, this suggests a concrete playbook rather than a product feature. For researchers, it suggests that the line between "what a model can do" and "what a model does by default" is more permeable than the "just train a bigger one" narrative assumes.
9. What this study cannot prove
Honest list, above the data rather than below it:
- One subject model, one reference pair. GPT-5.4 was the subject. Opus 4.7 and Gemini 3.1 Pro supplied the peer traces. Other subject-peer combinations are untested.
- One skill family produced the positive result. One cross-skill control returned null. Broader generalization is an open question.
- The judge panel found both arms equally correct. We cannot claim the scaffold produced better fixes. We claim it produced equivalent fixes more efficiently.
- Training-data overlap is unobserved. We can't distinguish "the model observed a pattern and followed it" from "the model recognized a pattern it already knew." The §5.5 self-recognition moment is suggestive but not conclusive.
- N=10 per arm is enough for directional claims on this single skill. It is not enough for provider rankings or broader benchmark claims.
- The observer (the author coding the traces) is Claude Opus 4.7. Pattern-selection bias is real; we mitigated it by freezing the coding rules before looking at any trace and using a deterministic analyzer, but a non-Claude observer might notice different patterns.
10. For agent-system builders — a reusable playbook
A procedure more than a product. Every step is something an engineering team can run in an afternoon:
- Pick a skill where your agent underperforms peers. Not a general "our agent is slow" complaint, but a specific skill, measurable, with peer data available.
- Collect traces from peers and the subject. Full tool-call sequences with pass/fail labels. Three runs per model is enough to see shape.
- Show the subject a labeled trace digest. Ask it to name what distinguishes passing from failing behavior, in one paragraph, written as an instruction a debugging agent could follow. One call. Fire-once. No silent retries if the output is weak — that's the real result.
- Paste the subject's answer into the subject's system prompt. Verbatim. No editing, no polishing.
- Measure rounds, correctness, and pass rate against a matched baseline. N=10 per arm is enough for directional claims. Matched conditions on everything except the scaffold.
The finding that matters here is not that the intervention worked. Many in-context prompting techniques work. The finding is that the subject model, given a view of its peers' behavior, articulated the correction itself, named its own observable error in the data without being asked to identify itself, and then followed its own instruction closely enough to cut its round count by nearly half.
A 101-word edit to a system prompt moved the model's behavior by 40.5%. Both the pattern and the instruction came out of the model, not us. The rest of the frontier-agent landscape is going to feel the pull of that asymmetry before long.
11. For business leaders — three decisions this changes
The case study is narrow. The implications for buying, building, and running agentic systems are broader, and they mostly cut against common intuitions about AI procurement.
11.1 Model selection is not one-dimensional
Aggregate leaderboard scores hide skill-specific behavior. In this study, GPT-5.4 was the fastest model on fix-broken-build (7.0 rounds vs Opus 7.7 and Gemini 11.0) and the slowest on fix-concurrency-bug (13.3 rounds vs Opus 10.7 and Gemini 10.3) — same benchmark, same conditions. If your agent's workflow exercises the skill where your chosen model is slow, upgrading to "the best on average" may leave the specific problem unsolved.
Decision that changes: evaluate vendors on your workflow's skills, not on their marketing benchmarks. Model comparison is a multi-dimensional problem now.
11.2 Cheap experiments often beat expensive migrations
The full project (a failed diagnostic arm, the primary intervention, and the generalization control) came in under $20 of API spend and a handful of hours of engineer time. Compare that to the scale of a typical vendor-swap project, or a fine-tuning engagement.
Before re-architecting around a different model, ask: is this a one-paragraph problem? On fix-concurrency-bug, it turned out to be. On fix-cross-file-bug, it didn't need fixing. Both answers were cheap to find.
Decision that changes: default to a prompt-level experiment before committing to a model swap or fine-tune. The experiment fits in a week of an engineer's calendar.
11.3 Measurement discipline is the enterprise-grade part
The 40.5% headline is only credible because the study had:
- a pre-registered plan committed before any experiment fired (no p-hacking possible),
- a matched-baseline comparison (not before/after on a moving environment),
- distribution reporting, not just means (you'll miss bimodal failures otherwise),
- an explicit check that fix correctness didn't regress while efficiency improved.
Without that infrastructure, a 40.5% improvement is indistinguishable from a 40.5% lucky streak. Agentic systems in production need this discipline wired in, or the optimization claims are decorative.
Decision that changes: the cheapest AI-infrastructure investment you can make this quarter is probably not a new model, a new vendor, or a new agent framework. It's measurement infrastructure — pre-registered thresholds, matched comparisons, distribution-aware dashboards — the stuff that tells you whether your improvements are real.
What not to take away
Do not pitch this as a productizable capability. The scaffold was inert on a second skill where the target pattern wasn't present. The method travels; the specific scaffold doesn't. "Habits transfer via observation" is a technique to try per-skill, where the specific pattern is present, not a general claim about how frontier models behave.
One-line version
Teams that run this procedure quarterly on their highest-impact skills will pull ahead of teams that wait for the next model release. Architecture is faster to move than capability, and the tools to exploit that asymmetry cost twenty dollars and an afternoon.
Source benchmark
This article is a follow-on to the frontier-3way benchmark, an April 2026 comparison of Claude Opus 4.7, Gemini 3.1 Pro, and GPT-5.4 across five agentic-coding skills. The three-model round counts, pass rates, and skill-by-skill comparison data cited throughout (§1, §2, §3, §4, and the cross-file baseline referenced in §7) come from that benchmark's published run. This study re-ran GPT-5.4 on two of its five skills, concurrency-bug and cross-file-bug, with a self-articulated scaffold prepended to its system prompt, and compared against a matched N=10 baseline per skill.