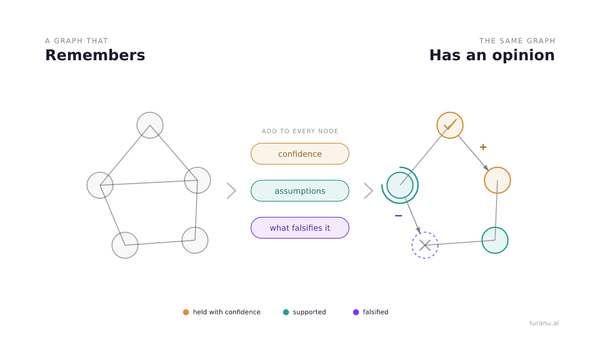
The four things you know about your own code

The code passed every test. It worked in staging. It worked in the demo. It shipped clean. Six hours later it took down checkout, on an input nobody had thought to try, on a path nobody had thought to look at, because the person who wrote it had been moving fast and the person who reviewed it had been moving faster. Afterward, in the post-mortem, someone asked the obvious question: how did nobody catch this? And the honest answer was the uncomfortable one. Everybody had caught a hundred things. This was not one of the hundred. It was the hundred-and-first, and nobody knew to look for it.
That gap, the space between the things you check and the things it would never occur to you to check, has a name. It comes from an unlikely place. And it has grown sharper teeth in the last two years, as more of the code we ship is written by a machine we are not watching closely.
A defense secretary, a 2x2, and your codebase
In 2002, Donald Rumsfeld stood at a podium and said something that got him a Foot in Mouth Award and, much later, a grudging kind of respect. He was talking about intelligence, but he could have been talking about your repository. There are things we know we know, he said. There are things we know we do not know. And there are things we do not know we do not know.
He did not invent the idea. Engineers at NASA and in defense procurement had been using the phrase "unk-unks" for unknown unknowns decades before Rumsfeld, with documented usage in reports from the 1970s. The carved-up version of knowledge it points to is older still, echoing a long-circulated epigram about four kinds of people, sorted by whether they know, and whether they know that they know. But the framing stuck because it is genuinely useful, and it lays out as a simple grid. One axis: are you aware of this piece of knowledge or not. The other: is it actually true, settled, verified, or not.
Four boxes fall out. Most people stop at three, because the fourth is the strange one. We will get to why the fourth is the one that matters most.
The grid maps onto the thing you actually care about, which is whether the code you are shipping does what you think it does.
The four things you know about your own code
Why this grid changed
For most of software's history, the grid had a comfortable shape. You wrote the code, so you mostly knew what it did. Your known-knowns box was large because writing something is the most reliable way to understand it. The dangerous boxes existed, but they filled slowly, because every line passed through your hands on the way in.
Then the machine started writing the code, and the grid tilted.
When you delegate the writing, you break the link between authorship and understanding. The code still gets written. It even gets written well, often better than you would have written it. But the knowledge of why it was written that way, what it assumes, what it quietly decided at the boundaries, no longer lands in your head as a side effect of typing. It lands in the repository instead. Your system now knows things you do not.
This is the move that inflates the two boxes you cannot see. And it is worth walking through each one honestly, because the instinct, "just review the AI's code," is right in spirit and useless in practice unless you know which box you are fighting.
The box you are pretending not to look at
Start with the strange fourth box, the one most versions of this idea leave out. The philosopher Slavoj Zizek has argued for a fourth category, the unknown known: things we do not know that we know, the disavowed assumptions we prefer not to examine.
In code, this is the most human failure on the grid, and the most common. It is the moment the change works on the first try and a small voice says that was suspicious, you should check why, and you say it works, ship it, and you move on. You knew. You half-knew. You chose the speed over the knowing. Every engineer has done this and most do it daily, and delegation makes it worse, because now there is so much more code arriving so much faster that stopping to interrogate each green checkmark feels like sand in the gears.
There is a second flavor of this box that is purely structural, no self-deception required. The machine made a choice, a good one, and wrote it into your system. A default value. A handled edge case. A pattern applied consistently across forty files. The knowledge is real and correct and in your codebase. It is simply not in you. You own a system that is, in a small but compounding way, smarter than you are about itself.
You drain this box two ways, and they map to its two flavors. The disavowed half is cultural, not technical: you learn to treat your own "ugh, but it works" as an alarm bell rather than a green light. The friction you keep rationalizing past is data. The embodied half is mechanical: you read the diff, but you read it as conversion rather than as a chore. Explaining to yourself why the machine chose what it chose is what moves the knowledge from the repository into your head. Better still, you make the machine explain it to you first, in plain language, before you accept a line.
The box you cannot aim at
Now the famous one. Unknown unknowns. Behavior nobody specified, triggered by inputs nobody tried, on paths nobody walked. This is the checkout outage. This is the change that worked in every test because the test for the failing case was never written, because the failing case was never imagined.
Delegation inflates this box for a brutal reason: the machine makes a thousand tiny decisions you never see. How to handle an empty list. What to do when two updates race. Which default to pick when you only specified one field of three. Each of those decisions is a place where the behavior at the boundary was chosen by something other than you, and you will not find out what it chose until something hits that boundary in production.
The mistake people make here is trying to think harder about this box. You cannot. That is the definition of the box. You cannot write a test for a failure mode you have not conceived, and if you could conceive it, it would already be in the box next door.
So you do not aim. You migrate. You run things that generate the inputs you would never think of, and you let them surprise you. Property-based testing is the sharpest tool for exactly this: instead of writing "check that updating the name field leaves the others alone," you write "for any single-field update, the other fields are unchanged," and the tool throws a thousand combinations at it until one breaks the rule. Fuzzing does the same for malformed input. Mutation testing checks whether your existing tests would even notice if the code were subtly wrong. And the oldest version, still the best: a second reviewer with no stake in the answer, whose only job is to ask "what breaks this," not "does this look right." None of these tools fix the bug. They do something more valuable. They drag it out of the box you cannot see and into the box you can.
The two boxes that are actually fine
The other two boxes need less from you, and naming them is mostly about relief.
Known unknowns, the things you know you have not checked, are the safe ones. "The machine touched the authentication flow and I have not reviewed it yet." That sentence is not a problem. That sentence is a to-do item. Risk you can see is risk you can schedule, assign, and burn down. The whole game is getting risk into this box, where it is visible, and out of the two boxes where it hides. The way you fill it deliberately is to make the work declare itself: before you accept a chunk of generated code, ask it what it assumed, what it did not handle, what it left untested. Every honest answer is a known-unknown you can now act on instead of a blind spot waiting in production.
And known-knowns, the things you have read and verified and can point to, are the goal. This is the only box you are trying to grow. The code you actually understand. The invariant you wrote down and the test that proves it holds. In hand-written software this box filled on its own, slowly, as a byproduct of the work. In delegated software, understanding tends not to accumulate automatically; you have to fill it on purpose, and everything else on the grid is just plumbing to move knowledge into it.
The one rule
The core asymmetry: in delegated work, every box drains toward known-knowns, and left to itself the delegation pumps the other way.
That reorients how you work. When you wrote everything by hand, the current ran in your favor: understanding accumulated whether you tried or not. Now the current runs against you. The machine pumps code, and therefore unexamined correctness and unconceived behavior, into the two boxes you cannot see, faster than you can read. Your entire quality practice in this mode reduces to one job: out-pump the current. Read the diff to drain the disavowed. Make the work declare its assumptions to drain the known-unknowns. Run the generators to migrate the unknown-unknowns into the light. And verify, deliberately, to grow the one box worth growing.
The outage was an unknown-unknown that a property test would have caught in seconds. But the deeper lesson was never about that one bug. It was that the grid had tilted under everyone's feet and nobody had changed how they worked to match. The tools were available. The current was simply stronger than the habit.
Know which box you are fighting. Then out-pump the current.
#AI #ProductStrategy #AgenticAI #SoftwareEngineering #GenerativeAI