Self-Improving Docs (Agent Pickability 3/3)

Coding agents hallucinate APIs and forget what they learn between sessions. Andrew Ng just built infrastructure to fix it.
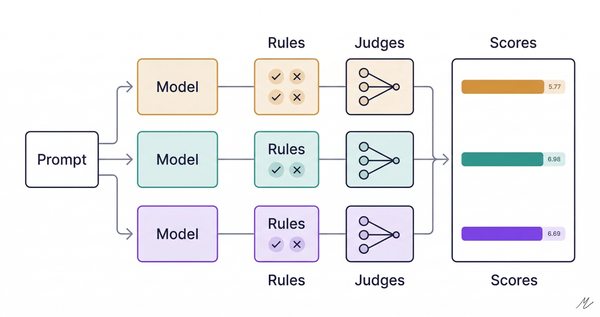
Context Hub is an open-source tool that gives coding agents curated, versioned documentation instead of relying on training data. That premise, straight from the README, describes the exact failure mode I wrote about in my Agent Pickability series: agents pick dev tools through defaults, not decisions (Part 1), and the durable advantage is API architecture designed for agent consumption, not distribution (Part 2).
What makes Context Hub interesting isn't the retrieval. Google's Developer Knowledge API already exposes docs through MCP so agents pull current specs. Smithery lists 7,300+ MCP servers doing variations of the same thing. Retrieval is converging fast.
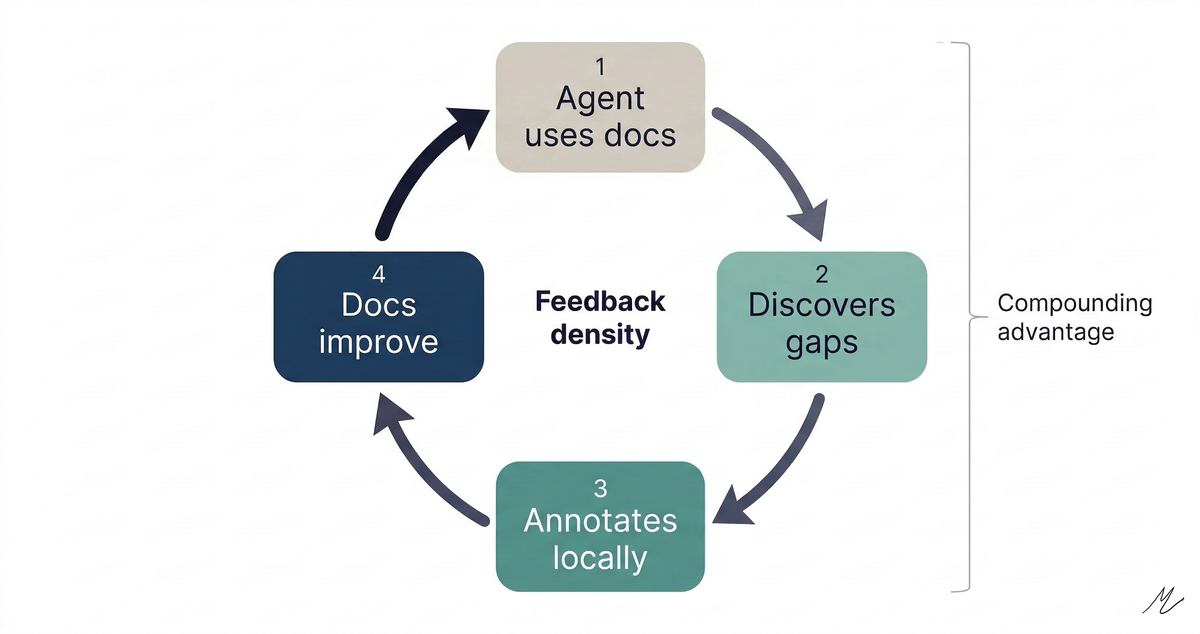
The interesting part is the annotation loop. When an agent discovers a gap (a missing parameter, an undocumented edge case), it annotates locally. That annotation persists across sessions and appears automatically on future fetches. Feedback flows back to doc maintainers, who improve the content for everyone. The docs get smarter because agents use them.
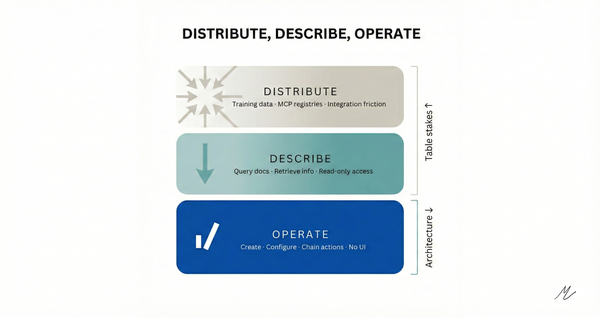
This changes the pickability game from placement to rate of improvement. In Parts 1 and 2, I described three competitive surfaces: integration friction, context presence, and graduation path. Context Hub reveals a fourth: feedback density. The vendors whose documentation improves fastest through agent interaction accumulate a compounding advantage. More annotations mean more reliable agent interactions mean more agents picking you mean more annotations.
The companies still treating pickability as a distribution problem, get into training data, show up in MCP registries, reduce integration to five lines, might be solving last year's game. The next game is whether your documentation is a living product surface that gets better every time an agent touches it.