Claude Wins on Its Own Skills — GPT-5.4 Costs Half as Much

Anthropic publishes skills for Claude Code: structured task definitions that tell the model what to build and how. They're designed for Claude. I ran them on GPT-5.4 and Gemini 3.1 Pro too. Claude won.
Claude Opus 4.6 averaged 0.825 across four Anthropic skills, against GPT-5.4 at 0.814 and Gemini 3.1 Pro at 0.768. The gap is narrow at the top — 0.011 points between first and second — but it showed up consistently on the hardest tasks. Gemini was the only model to fail a skill outright.
This is a pure generation benchmark. Each model gets a single prompt (the skill instructions plus a test input) and produces its complete output in one shot. No tool use, no iteration, no agentic loop. Just: here's the task, generate the deliverable.
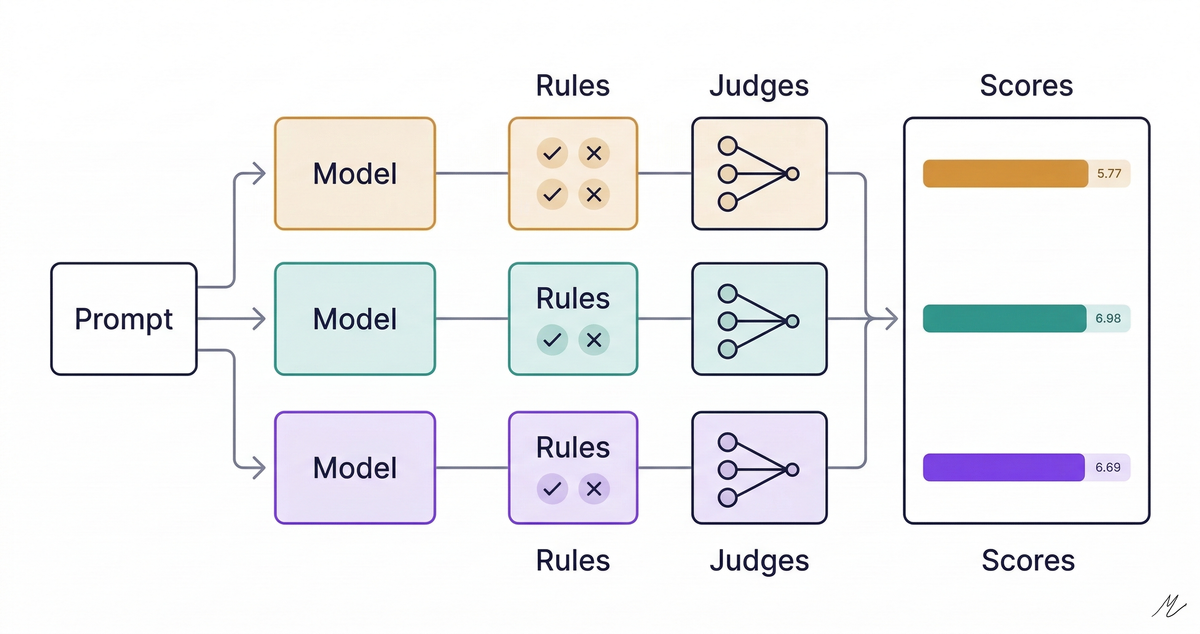
I built a testing rig called EvalRig to score the outputs. Each response goes through two layers: deterministic rules (60% of the final score) that check whether the output contains required patterns: does the code import the right library, does it include error handling, does it use Excel formulas instead of hardcoded values. These are binary, reproducible, and free to run. The second layer (40%) is an ensemble LLM judge: all three frontier models independently grade each output on relevance, completeness, and accuracy. The median of those three judge scores becomes the final component. No model grades its own homework unchecked.
What Got Tested
Four of Anthropic's published skills, chosen because they're self-contained enough to evaluate as single-shot generation tasks. No file system access or tool calls required. Each skill has a defined test input specifying exactly what to produce.
- MCP Server Builder (
mcp-builder): build a complete MCP server for the GitHub API (REST API v3) in TypeScript — six tools for repos, issues, and PRs, with Zod schemas, auth via environment variable, paginated results, error handling, and tool annotations. - Frontend Design (
frontend-design): build a real-time analytics dashboard landing page for "Pulsewave", an API monitoring platform. Dark theme, hero section, mock metrics visualization, feature grid, pricing tiers, responsive layout, staggered animations. Single HTML file, no external libraries. - Skill Creator (
skill-creator): write a complete SKILL.md for a changelog generator — YAML frontmatter, structured instructions for parsing conventional commits, examples, edge cases for monorepo structures, and support for multiple output formats. - Excel Generator (
xlsx): produce Python code using openpyxl to build a 3-year SaaS startup financial model with three sheets (Assumptions, P&L, Summary), Excel formulas referencing across sheets, financial color coding, and proper number formatting.
The MCP server task requires understanding a protocol spec. The financial model requires Excel formula semantics, not just Python. The frontend asks for production-quality responsive design, not a div with a border.
The Scores
| Model | Avg Score | Pass Rate | Total Cost | Avg Tokens |
|---|---|---|---|---|
| Claude Opus 4.6 | 0.825 | 4/4 | $1.03 | 8,955 |
| GPT-5.4 | 0.814 | 4/4 | $0.48 | 6,042 |
| Gemini 3.1 Pro | 0.768 | 3/4 | $0.31 | 4,009 |
Eleven of twelve runs passed. Gemini failed the MCP builder skill. Total benchmark cost including thirty-six judge calls: $1.82.
Where They Diverged
MCP Server Builder was the hardest skill, and the one that separated the models. Claude Opus led with 0.83, producing 9,896 tokens of working TypeScript that passed all six deterministic rules. GPT-5.4 followed at 0.79, also passing all rules in roughly half the tokens (4,587). Gemini failed at 0.67: it started building the server correctly — proper SDK imports, Zod schemas, API client with auth — but 3,605 tokens in, it veered off-track and started generating evaluation XML (Q&A pairs about the server) instead of finishing the tool implementations. It never reached the server.tool() registration calls, failing the has_tool_definitions rule. This wasn't a token limit issue; the model simply lost coherence on a long, structured code generation task. I re-ran Gemini on this skill three times — same score (0.67), same failure mode every time. It's reproducible.
Frontend Design was a dead heat: all three scored 0.75. Rules were clean across the board: every model produced valid HTML structure, responsive CSS, animations, and semantic markup. The judges were harsh on completeness (0.0-0.25 across all models and all judges), reflecting the gap between what these skills ask for and what a single-shot response can deliver. When the task is well-specified and visual, the models converge — but none of them fully satisfy the judges.
Skill Creator was the meta-skill: use an AI to write instructions for an AI. GPT-5.4 led at 0.92, followed by Claude at 0.88 and Gemini at 0.86. All three showed strong relevance and accuracy from the judges. Gemini produced the most concise response at 1,117 tokens but failed the has_edge_cases rule — its output didn't explicitly address error scenarios. GPT-5.4 at 4,264 tokens struck the best balance between coverage and precision.
Excel Generator showed a clear winner. Claude scored 0.83 with 5,764 tokens: a complete openpyxl script with all three sheets, cross-sheet formula references, financial color coding, and proper formatting. GPT-5.4 and Gemini tied at 0.79. All three passed every rule. The judge scores were close — the difference came from Claude's output including more of what the skill asked for: full P&L structure with 36 monthly columns, summary metrics with formulas referencing the P&L sheet, and yellow-highlighted assumption cells.
The Verbosity Question
Claude Opus generated an average of 8,955 tokens per skill. GPT-5.4 averaged 6,042. Gemini averaged 4,009. Claude's outputs were 1.5x longer than GPT's and 2.2x longer than Gemini's.
On the harder tasks, verbosity correlated with quality. On MCP builder, Claude's 9,896 tokens scored 0.83 while Gemini's 3,605 tokens scored 0.67. On Excel, Claude's 5,764 tokens scored 0.83 while GPT and Gemini scored 0.79 with ~3,000 tokens each. For complex, multi-part code generation tasks, more tokens meant more complete implementations.
But this doesn't hold universally. On Skill Creator, Gemini's 1,117 tokens scored 0.86 while Claude's 3,775 scored 0.88 — nearly the same quality at a third the tokens. On Frontend Design, all three scored identically despite a 2x token range. The pattern: verbosity helps on tasks with many structural requirements (sheets, tools, schemas), but doesn't move the needle on tasks with simpler output structure.
The cost picture remains steep for Claude. At $15 per million output tokens:
- Gemini: 2.48 score per dollar
- GPT-5.4: 1.70 score per dollar
- Claude Opus: 0.80 score per dollar
Claude delivers the highest quality but at 3x the cost-efficiency of Gemini. Whether that tradeoff makes sense depends on what you're building.
What the Judges Agreed On
Completeness was the universal weak point. Across all twelve runs, the median completeness score from judges was 0.0-0.5. Every model struggled to deliver everything these skills ask for in a single response. The skills were designed for agentic execution: iterative tool use, file reads, multi-step workflows. Running them in single-shot text mode means the model has to produce everything at once, which is a harder task than the skills were designed for.
Relevance was universally high (0.75-1.0). Every model understood what was being asked. Accuracy varied: Claude and Gemini scored higher on accuracy for code-generation tasks, while GPT-5.4 showed the most consistent accuracy across task types.
One finding worth calling out: judge tendencies shift depending on what's being evaluated. On Skill Creator, all three judges scored relatively generously — completeness scores of 0.25-0.75. On Frontend Design, every judge gave completeness of 0.0-0.25 for every model. The judges agreed the models understood the tasks (high relevance) but consistently flagged incomplete deliverables. This is the strongest argument for using a median across multiple judges rather than trusting any single model's opinion.
What This Means
For teams choosing models today: Claude Opus 4.6 delivers the highest quality on complex, multi-part generation tasks, but at significant cost. GPT-5.4 offers the best balance — 98% of Claude's quality at half the price. Gemini 3.1 Pro is the budget option and handles simpler tasks well, but struggles with long, structured code generation where coherence matters.
If you need agentic execution with tool use, these results don't yet apply. That benchmark is coming. These skills were designed for Claude Code's agentic loop: tool calls, file operations, iterative refinement. Running them as single-shot generation tasks puts every model at a disadvantage, but especially models whose style expects iterative execution. The next round of benchmarks will enable tool execution.
The model selection question has shifted. It's no longer "which model is smartest" but "which model fits your execution pattern and budget." Single-shot generation favors thoroughness on hard tasks and concision on simple ones. You need to test on your own tasks, with your own criteria.
Methodology
Each model receives the same prompt: the skill's instructions as a system-level context, plus a detailed test input describing exactly what to generate. The model produces its complete response in a single shot at temperature 0.0. No retries, no tool access, no multi-turn interaction.
Scoring is two layers. The rules layer (60% weight) uses deterministic pattern matching against the raw output: does the MCP server include tool definitions, does the Excel code use formulas, does the HTML have responsive media queries. Each rule is binary (pass or fail), reproducible, and free to run. The judge layer (40%) sends each output to all three frontier models with identical rubrics for relevance, completeness, and accuracy. The median of the three judge scores becomes the final judge component, neutralizing individual model bias and self-favoritism.
Skills are Anthropic's published definitions, each with an eval.yaml that specifies the deterministic rules, judge configuration, and test inputs. Single run per model per skill; production benchmarks should average multiple runs.
The latest benchmark results are always available at evalrig.ai. More benchmarks coming as new models ship; next up is the same skills with tool execution enabled.