Before You Build an Agentic AI Product, Build an MCP Server (Part 1/2)

A Framework for Deciding If Your Product Should Be Agentic
When someone brings me a product idea, my first questions are always the same: Who's the customer? What's the pain? Is there a market? Will they pay?
Do that work first. No shortcuts.
But once you've validated the problem, a new question emerges — especially now, when every pitch deck has "AI agent" somewhere on slide three: should this product actually be agentic?
Not every product that could be an agent should be. Agentic architecture adds complexity: orchestration logic, state management, human-in-the-loop boundaries, context limits, cost unpredictability. If you don't need it, you're building liability, not leverage.
So how do you know?
I've been using a simple filter: build the MCP server first.
MCP servers are the tool layer for agentic systems — the interface between what an agent can reason about and what it can actually do. Building one takes days, not months. And it reveals the true shape of your architecture before you've committed to infrastructure.
Two ideas, same filter
Let me illustrate with two examples. Both were product ideas where agentic architecture seemed like a natural fit. Both went through the same filter: build the MCP server, see what it reveals.
Idea A: Human-in-the-loop translation workflow
The pitch: a tool that helps translate literary essays from English to Tamil, with human review at each step. Paragraph-by-paragraph workflow, glossary management, style consistency, learning from corrections over time.
I built the MCP server. The implementation surfaced real orchestration complexity: state persistence across sessions, tiered retrieval to manage context limits, batch operations for efficiency, learning loops that captured corrections. Nine distinct patterns emerged — each one a decision production agents need.
Verdict: genuinely agentic. The workflow requires an LLM to orchestrate tools, manage state, and adapt based on intermediate results. A traditional app with an "AI assist" button wouldn't work — the agent is the product.
But here's the catch: it's still a personal tool, not a defensible product. The complexity was real, but the moat was my accumulated glossaries and patterns. Useful to me, not a platform. Anyone with the same architectural patterns could rebuild it for their own language pair and translation style.
Idea B: Personal movie recommendations across streaming platforms
The pitch: an agent that searches my aggregated watchlist (3,000+ titles across Kanopy, Amazon, Hulu, Hoopla), learns my taste over time, and surfaces recommendations based on mood, constraints, and what's actually available tonight.
I built the MCP server. Different shape entirely. The workflow was simple — search, filter, recommend. The hard part was obvious from the start: data access.
Getting availability across platforms. Caching expensive score lookups. Tracking what's actually streamable versus what's disappeared. Building hybrid retrieval that combines semantic search ("slow-burn thriller, visually striking") with hard filters (under two hours, on Kanopy, critically acclaimed).
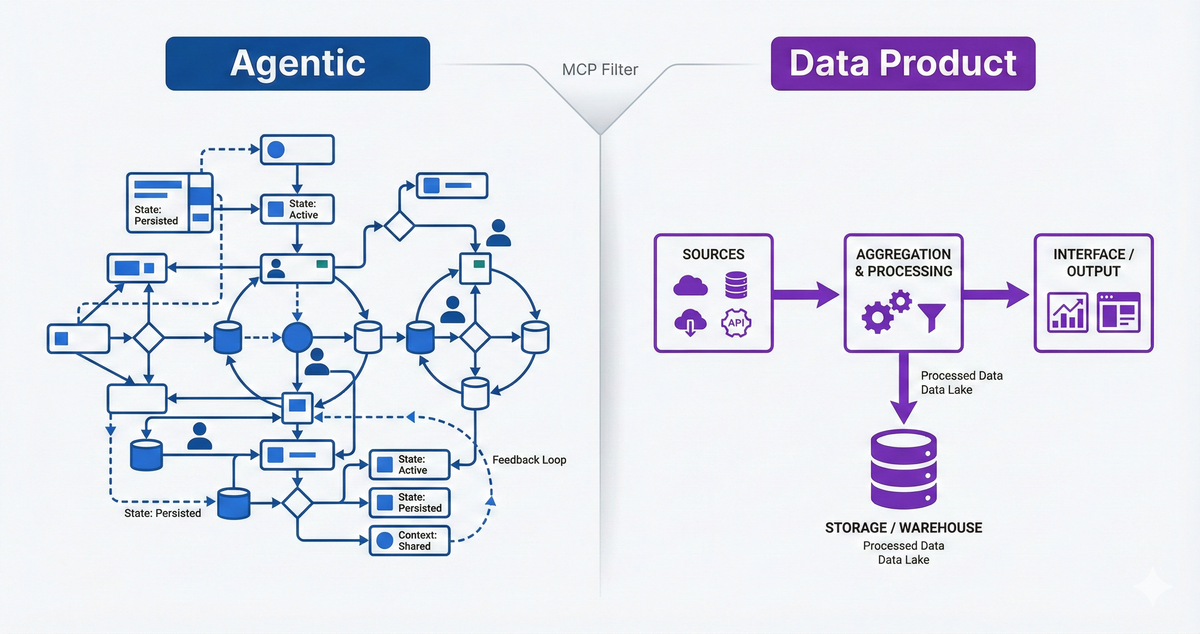
Verdict: not really agentic. The "agent" part is trivial — a thin orchestration layer over search and filtering. The value is in data aggregation, availability tracking, and the taste model that compounds over time. This is a data product with a conversational interface, not an agentic AI product.
That doesn't make it less valuable. It just means "agentic" is the wrong frame. The hard problems are data engineering and integration, not agent architecture.
What the filter reveals
Same process, different verdicts:
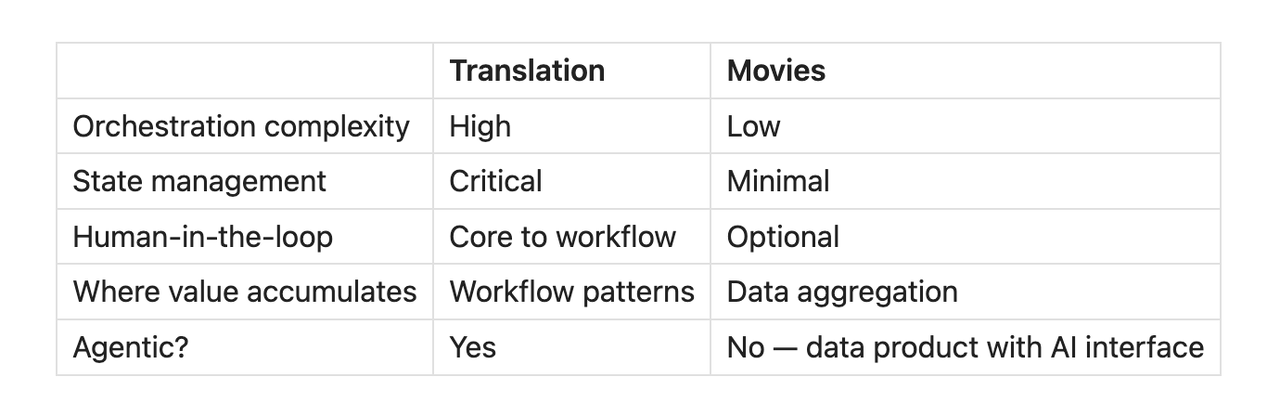
The MCP build forced both questions to the surface. For translation, it revealed that agentic architecture was genuinely necessary — and that the patterns themselves were the learning. For movies, it confirmed that the "agent" framing was misleading. The hard problems lived elsewhere.
The questions MCP answers
There's a pattern to what this process reveals:
Is there real orchestration complexity? If your MCP implementation is trivial - a handful of tools in a predictable sequence - you might not need an agent. You might need a well-designed traditional app with some AI features.
What should the agent handle vs. deterministic code vs. human judgment? You discover this empirically. It matters for cost, latency, and reliability. It also reveals whether you're building an agentic product or a traditional product with an AI label.
Where are the human-in-the-loop boundaries? MCP forces you to define approval points. Every time you think "a human should review this before proceeding," you're identifying a trust boundary.
Where does value actually accumulate? The prototype reveals whether your moat is in workflow design, data access, domain expertise, or the agent architecture itself.
The wrinkle worth naming
This filter tells you whether a product should be agentic. It doesn't tell you whether it should be a product.
The translation MCP server revealed genuine agentic complexity - and also revealed it was a personal tool with no defensible moat. The movies MCP server revealed it wasn't really agentic - but the data aggregation underneath might still be a product worth building.
Architecture validation and business validation are different questions. Do both.
The filter
My heuristic: if the MCP server takes a day and the orchestration is trivial, it's probably not an agentic product. Might still be a good product — just not one where agent architecture is the differentiator.
If it surfaces real complexity — branching logic, state persistence, learning loops, human-in-the-loop boundaries — then agentic might be the right frame. Worth the next phase of investigation.
Either way, you've learned something in days, not months. And you have a working tool regardless.
Part 2 explores what these two builds revealed — the specific patterns that separate demo agents from production systems. Same filter, two domains, overlapping lessons.*