Applying the MCP Filter: Two Products, Different Verdicts (Part 2/2)

When the Same Patterns Reveal Different Products
I built two MCP servers to test the same question: should this product be agentic? Same patterns applied to both. One confirmed the agentic hypothesis. The other falsified it. What I'd been calling a "movie recommendation agent" was actually a data product with a conversational interface.
The patterns themselves were the diagnostic.
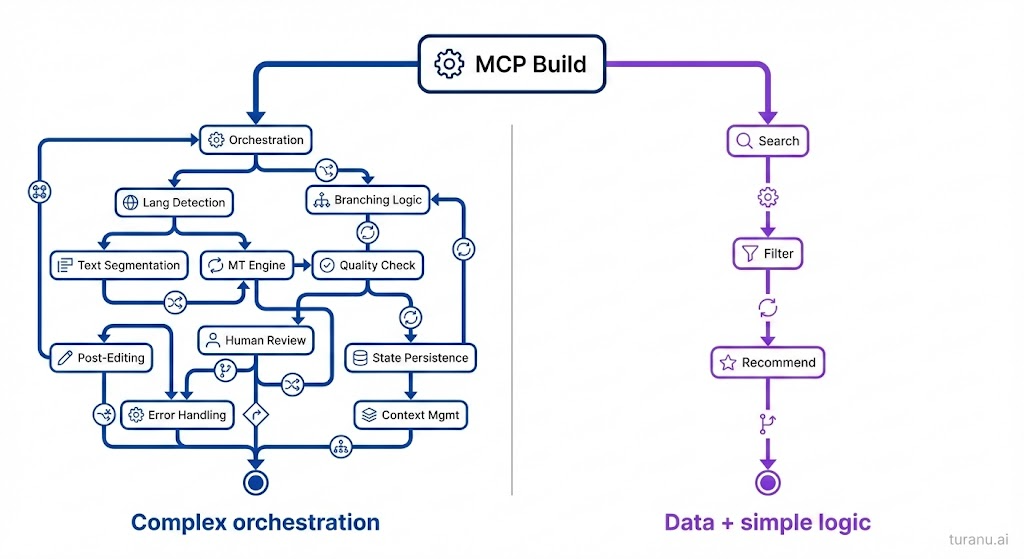
One surfaced genuine architectural complexity: orchestration, state management, human-in-the-loop boundaries. The other collapsed into search and filtering with a thin orchestration layer on top. The whiteboard version looked identical. The build exposed the difference.
The forcing function: context economics
Both builds hit the same wall: token overhead. For the translation workflow with 65 paragraphs and four tool calls per step, that's 78,000 tokens before any actual work. The context window couldn't hold it, so the naive implementation simply failed.
Making both workflows fit within those limits required applying nine architectural patterns. Those patterns revealed which product was genuinely agentic.
Translation: Applying the Patterns
The translation workflow was human-in-the-loop paragraph-by-paragraph translation from English to Tamil, with glossary management, style consistency, and learning from corrections over time.
Efficiency patterns: making it fit
The first fixes were about compression. Combined operations cut three tool calls (get paragraph, translate, save) into one. Batch operations handled twelve citation paragraphs in one call instead of twelve separate calls. Lean responses returned only confirmation and next-action hints instead of echoing everything back.
These three patterns cut context usage significantly by finding the workflow's atomic units: the operations that always occur together. These units only become visible under constraint.
Architectural patterns: what the workflow actually needs
The next patterns weren't about efficiency but about making the agent architecture actually work.
Tiered retrieval replaced one "get everything" tool (30,000 tokens) with three options: progress summary (~100 tokens), current paragraph with context (~500 tokens), or full bilingual review (use sparingly). This is progressive disclosure for AI systems, and agents work better when they can drill down rather than drown.
State persistence made the workflow resumable by auto-detecting existing state on initialization and persisting after every operation. Every real workflow gets interrupted. The prototype exposes whether state management is critical or incidental, and for translation, it was critical.
Smart defaults and workflow guidance added a translate_next() tool that infers what "next" means, and every response includes a hint like "Next: paragraph 17" or "All done, use export()." Workflow guidance isn't just for users because your agent needs it too.
External knowledge injection moved glossaries and style preferences to files loaded at session initialization, so you can inject them when needed and edit without code changes. The prototype reveals the boundary between logic and knowledge, a boundary your agent architecture will need to respect.
Incremental learning loops captured corrections as patterns, persisted them across sessions, and injected them alongside glossaries so the same phrasing mistake doesn't recur forever. This is the difference between a tool and an agent that gets better.
The compound effect
These patterns reduced context usage by 90%:
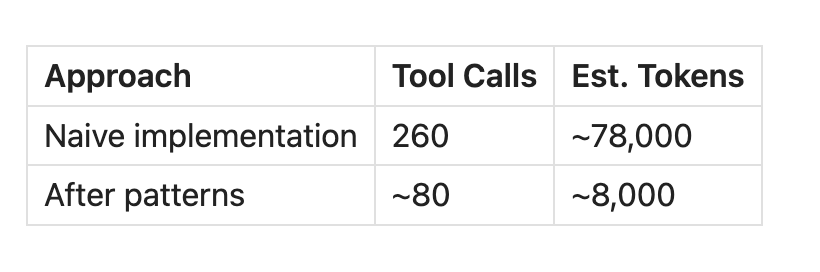
That 90% isn't about optimization but about fit. The naive version exceeds context limits so the agent can't complete the workflow, while the optimized version works comfortably.
But more importantly, the workflow was still complex. Even optimized, it required orchestration logic across 65 steps, state persisting across sessions, human-in-the-loop approval at every paragraph, learning loops shaping future behavior, and branching based on intermediate results.
The agent is the workflow. This is genuinely agentic.
Movies: Same Patterns, Different Verdict
I applied the same filter to movie recommendations. 3,000+ titles across streaming platforms, with the pitch being an agent that searches my watchlist, learns my taste, and surfaces recommendations based on mood and what's actually available tonight.
I applied the same patterns: batch lookups for availability checks, lean responses returning minimal info (title, year, one-line hook) with a separate tool for full details, tiered retrieval for search results, state persistence caching expensive critic score lookups, external knowledge injection for taste preferences, and learning loops logging queries and ratings.
The patterns made the system faster and cheaper, context usage dropped, and the experience improved. But applying them exposed the real question: where was the agent?
The orchestration was trivial
Look at the workflow: search, filter, recommend, with no branching logic based on intermediate results, no complex state management across steps, and no human-in-the-loop approval points shaping subsequent behavior. The "orchestration" is a thin layer over search and filtering.
Compare to translation: 65 paragraphs, each requiring retrieval, translation, review, and approval, with state persisting across steps and human feedback shaping subsequent translations. The agent is the workflow.
Movies is different. You search, filter, and show results, then maybe drill into details or log a review afterward. The workflow is linear and simple.
The hard problems weren't agent problems but data problems: aggregating availability across platforms, caching external lookups, building hybrid retrieval that combines vectors with metadata filters, and accumulating a taste model over time.
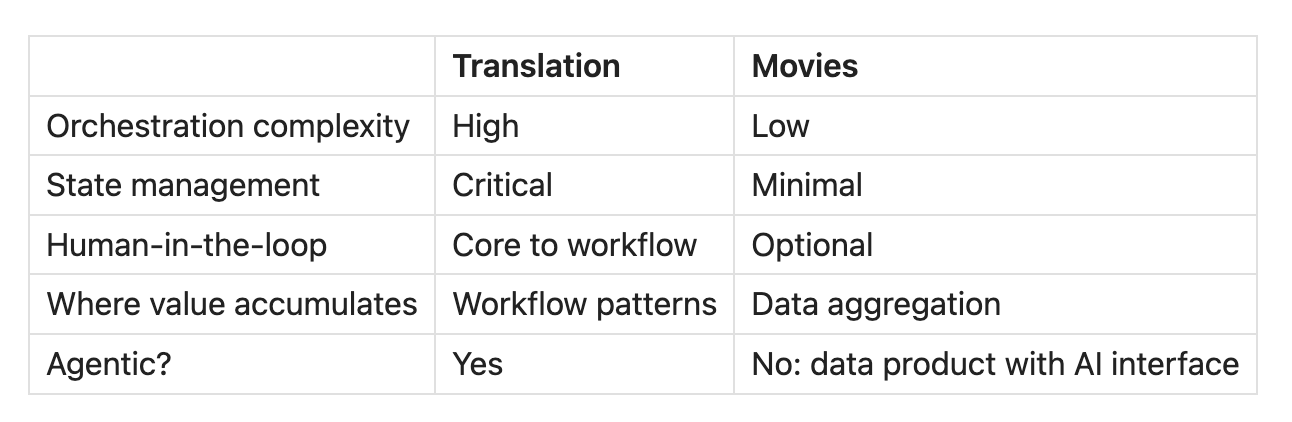
The MCP build revealed that "movie recommendation agent" was the wrong frame. This is a data product with a conversational interface, where the value is in aggregation and the taste model that compounds, not in orchestration.
That doesn't make it less worth building. It just means agentic architecture isn't the differentiator.
The diagnostic value
Same patterns, different verdicts.
The patterns aren't just optimization techniques but architecture detectors. When you apply them and orchestration stays trivial, that's signal. When the hard problems are about data access and the "agent" is just a thin query layer, that's signal too.
When you apply them and the workflow is still complex (still requires branching logic, state management, human-in-the-loop boundaries), that's different signal. That's genuinely agentic.
The patterns reveal structural properties:
Context is a budget. How you handle it reveals whether you have real orchestration complexity.
Atomicity matters. Finding the real units of work shows where the workflow logic actually lives.
State is product. Workflow state that shapes next steps (agentic) is different from world state that persists across sessions (data product).
Learning surfaces exist. Learning from corrections that shape future workflow behavior (agentic) is different from learning user preferences (personalization).
The whiteboard design for the movie system looked agentic. The build revealed it wasn't.
The question to ask anyone pitching an "AI agent": what happens when you optimize for context? Does the orchestration stay complex, or does it collapse into a query layer?
The answer tells you what you're actually building.
This is Part 2 of a two-part series. Part 1 covers the framework: using MCP to determine whether a product should be agentic, with these two examples as test cases.