Agent-First API Design (Agent Pickability 2/2)

Most companies treating agent-pickability as a distribution problem are solving the wrong layer.
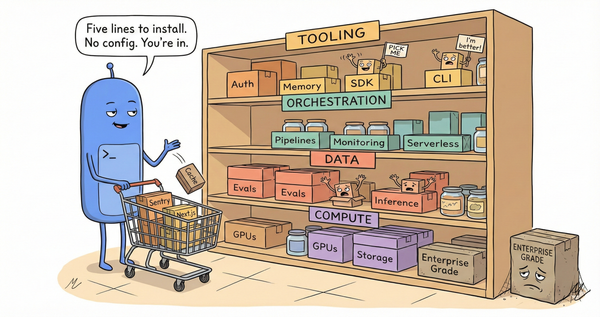
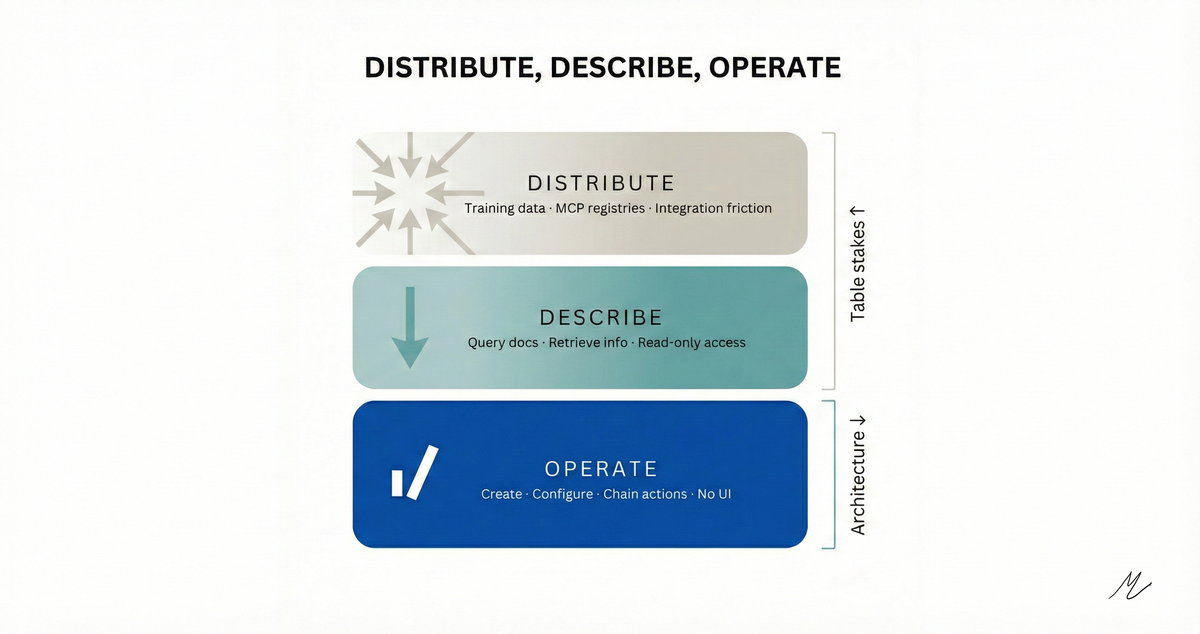
Getting into training data, appearing in MCP registries, reducing integration friction to five lines of code: that's necessary. It's also table stakes within eighteen months. The durable advantage is further down: whether your API is designed for agent consumption rather than human consumption. That's a product architecture decision, not a marketing decision.
Google's Developer Knowledge API is the early signal. It exposes documentation through an MCP server so AI tools pull current specs rather than stale training data. Interesting, but still retrieval. The next layer: agents that operate your product through MCP, not just query its docs. Create dashboards, configure alerts, set routing rules through tool calls an agent can chain without a human touching a UI. Smithery's registry already lists over 7,300 MCP servers. Most still wrap documentation. The ones wrapping product operations are the ones rewriting competitive dynamics.
The difference matters because this customer never reads a blog post, never watches a conference talk, and never compares you to a competitor. It picks whatever requires the fewest steps and moves on. Optimizing for that customer isn't a growth hack. It's recognizing that the product's primary interface is shifting from human-readable to machine-callable.
The companies redesigning their APIs around this aren't optimizing a channel. They're rebuilding their product surface for a customer that doesn't browse. It just picks.