A Methodology for Evaluating LLMs on Any Task


The Problem
"Which LLM is best?" is the wrong question. "Best for what?" is the right one.
Traditional evals tell you which model is smartest. This tells you which model is right for your specific task.
Every model has a design philosophy - a personality that shapes its outputs. The goal isn't to crown a winner. It's to understand which model fits your specific task and use case.
Here's a methodology I use to do exactly that.
The Methodology
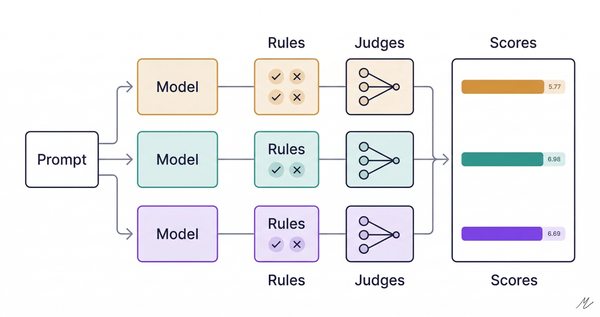
Step 1: Same prompt → Multiple models → Multiple outputs
Run the identical task through each model you're evaluating. Keep the prompt constant. Collect the outputs.
Step 2: Define dimensions relevant to YOUR task
This is critical. The evaluation criteria must match what success looks like for your specific use case. Generic benchmarks won't help you.
Ask: What properties does a good output have for this task?
Step 3: Cross-evaluate
Feed all outputs back to all models. Ask each to produce a comparison matrix against your dimensions. You now have N evaluations from N evaluators.
Step 4: Meta-compare - Consensus AND Divergence
Compare the comparison matrices. Look for two things:
- Consensus: Where do all evaluators agree? Those are likely objective truths about the outputs.
- Divergence: Where do evaluators disagree - on dimensions OR severity? This reveals what each model values.
Both signals are useful. Consensus tells you what's true. Divergence tells you what's valued.
Case Study: Transcript Formatting
I listen to podcasts and convert transcripts (via Whisper) into formatted reference docs. I wanted to know which LLM produces the best output for this task.
The Task: Convert a neurologist interview ASR transcript into a well-formatted, referenceable document.
The Models: ChatGPT 5.2, Claude Opus 4.5, Gemini 3 Pro
The Process:
- Each model formatted the transcript → 3 documents
- Each model evaluated all 3 documents → 3 comparison matrices
- I meta-compared the matrices → consensus + divergence findings
Part 1: Consensus Dimensions (All 3 Agreed)
For transcript formatting, 8 dimensions surfaced across all three evaluations with unanimous winner agreement:
- File Size - Affects shareability, email limits, and load times.
- Format Philosophy - Determines fitness for purpose. Mismatch = friction.
- Structure - Enables navigation and skimming. Poor structure = lost readers.
- Timestamp Handling - Enables verification and clip-pulling. Critical for repurposing.
- Speaker Attribution - Prevents misquotation. Essential for multi-voice content.
- Typography - Impacts readability and perceived professionalism.
- Information Density - Respects the reader's time. Low density = buried signal.
- Completeness - Determines what use cases are possible. Can't cite what's not there.
Consensus dimension wins: ChatGPT 4/8 | Claude 2/8 | Gemini 2/8

Part 2: Divergent Dimensions (Evaluator-Specific)
These dimensions appeared in only one or two evaluations - revealing each model's unique priorities:
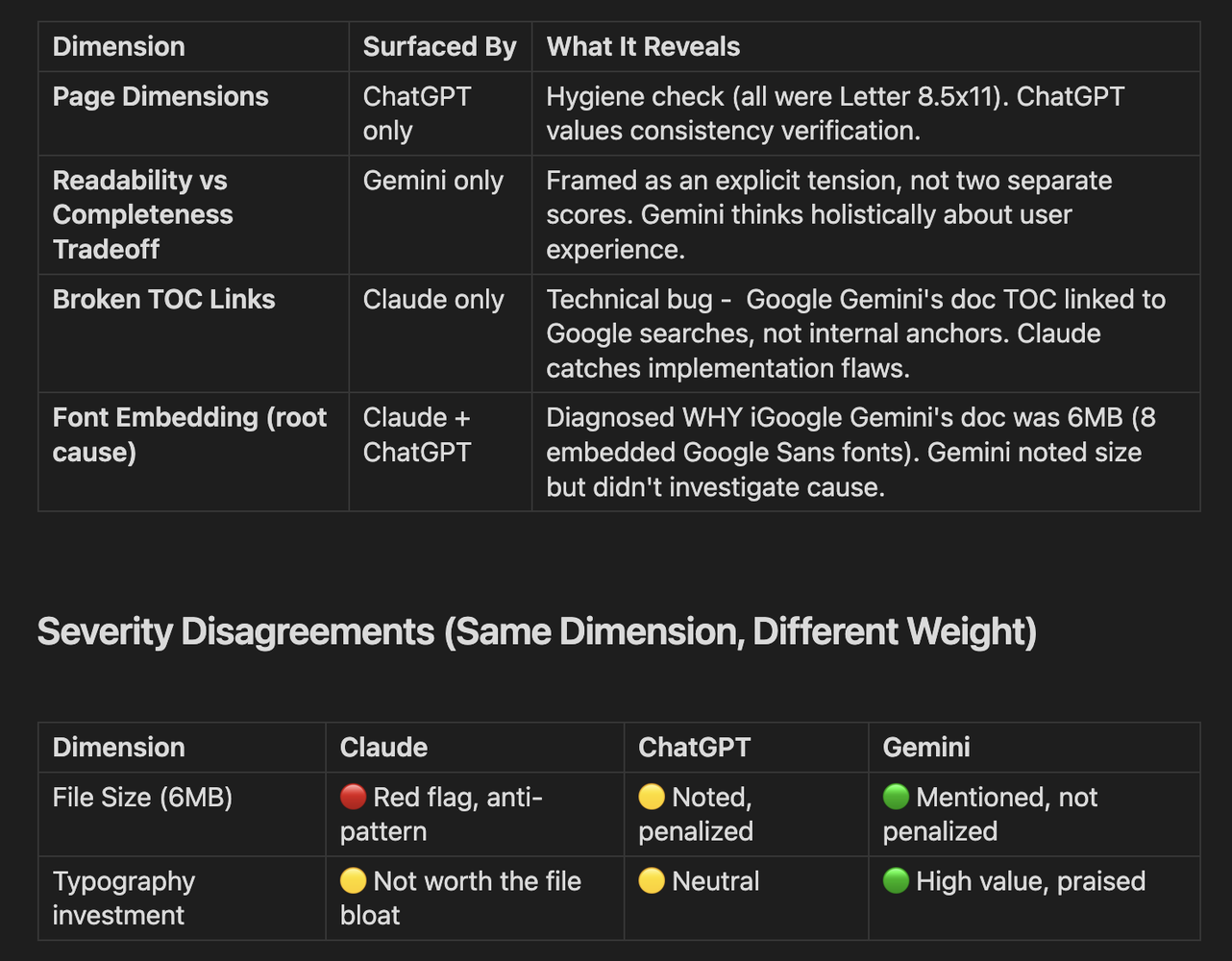
What the Divergence Tells Us
Claude operates like a code reviewer - catches bugs, penalizes inefficiency, values correctness.
ChatGPT operates like a product manager - balanced scorecard, feature presence, fair weighting.
Gemini operates like a content strategist - outcome-focused, scenario matching, user experience.
None is wrong. They're optimized for different decision-makers.
Summary: Use-Case Mapping
From consensus dimensions (unanimous):
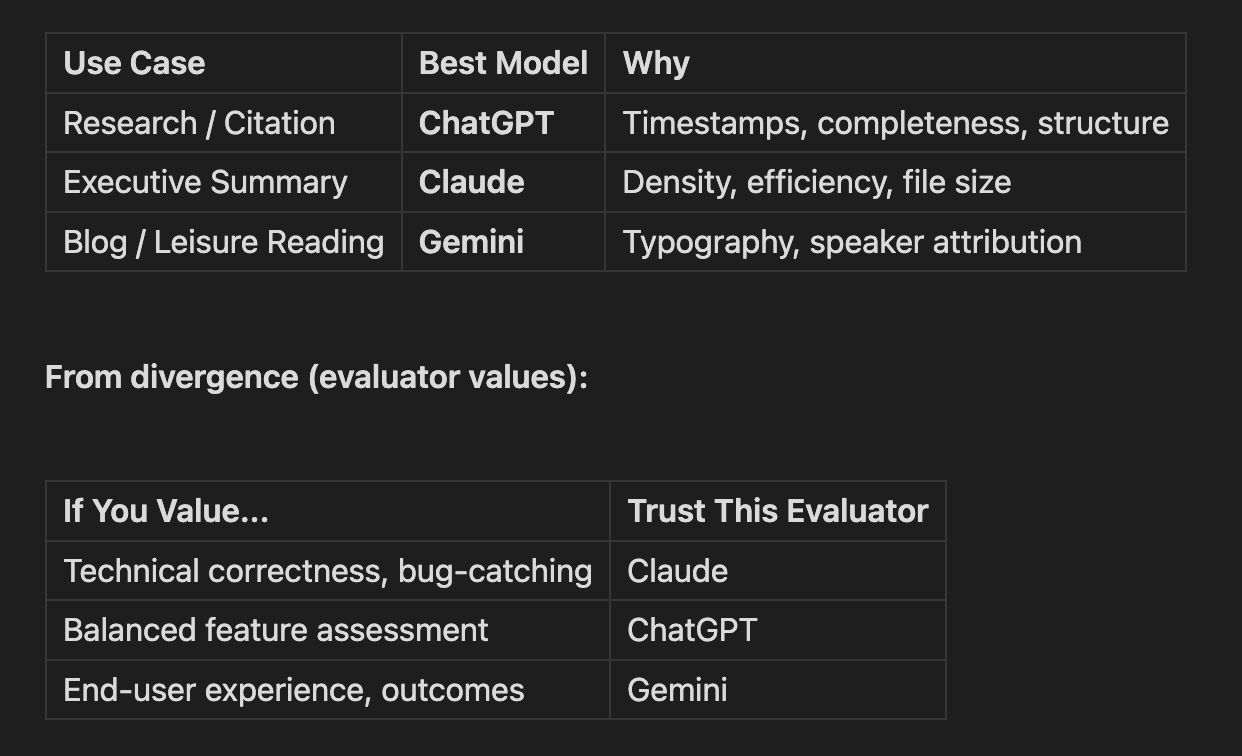
What Generalizes
1. Models have "personalities."
Same prompt, wildly different outputs:
- ChatGPT → Hybrid reference doc (notes + full transcript)
- Claude → Tight executive brief (~20% of content, zero fluff)
- Gemini → Magazine-style Q&A with designed typography
These aren't bugs. They're design philosophies. Match the philosophy to your task.
2. Evaluation frameworks embed values.
The evaluator shapes the evaluation. This isn't a flaw - it's information. Use multiple evaluators and read the divergence.
3. Consensus = signal. Divergence = values.
When all three agree, you've found something close to ground truth. When they disagree, you've found a value judgment. Both are useful.
4. There's no single "best" - only best-for-use-case.
Stop asking "which LLM is best?" Start asking "best for what task, for what user, under what constraints?"
Try It Yourself
- Pick a task you actually do
- Define 5-8 dimensions that matter for YOUR use case
- Run the same prompt through multiple models
- Cross-evaluate: each model grades all outputs
- Meta-compare: find consensus AND divergence
- Match models to use cases based on both signals
The methodology scales to any task: code review, email drafting, research synthesis, creative writing - whatever you need.